

UrbanKaoberg.com - Part I: There And Back Again
I built UrbanKaoberg.com in less than a month with AI. This piece is about my journey down one of the most frenetic, creative rabbit holes I have experienced and my learnings from it.

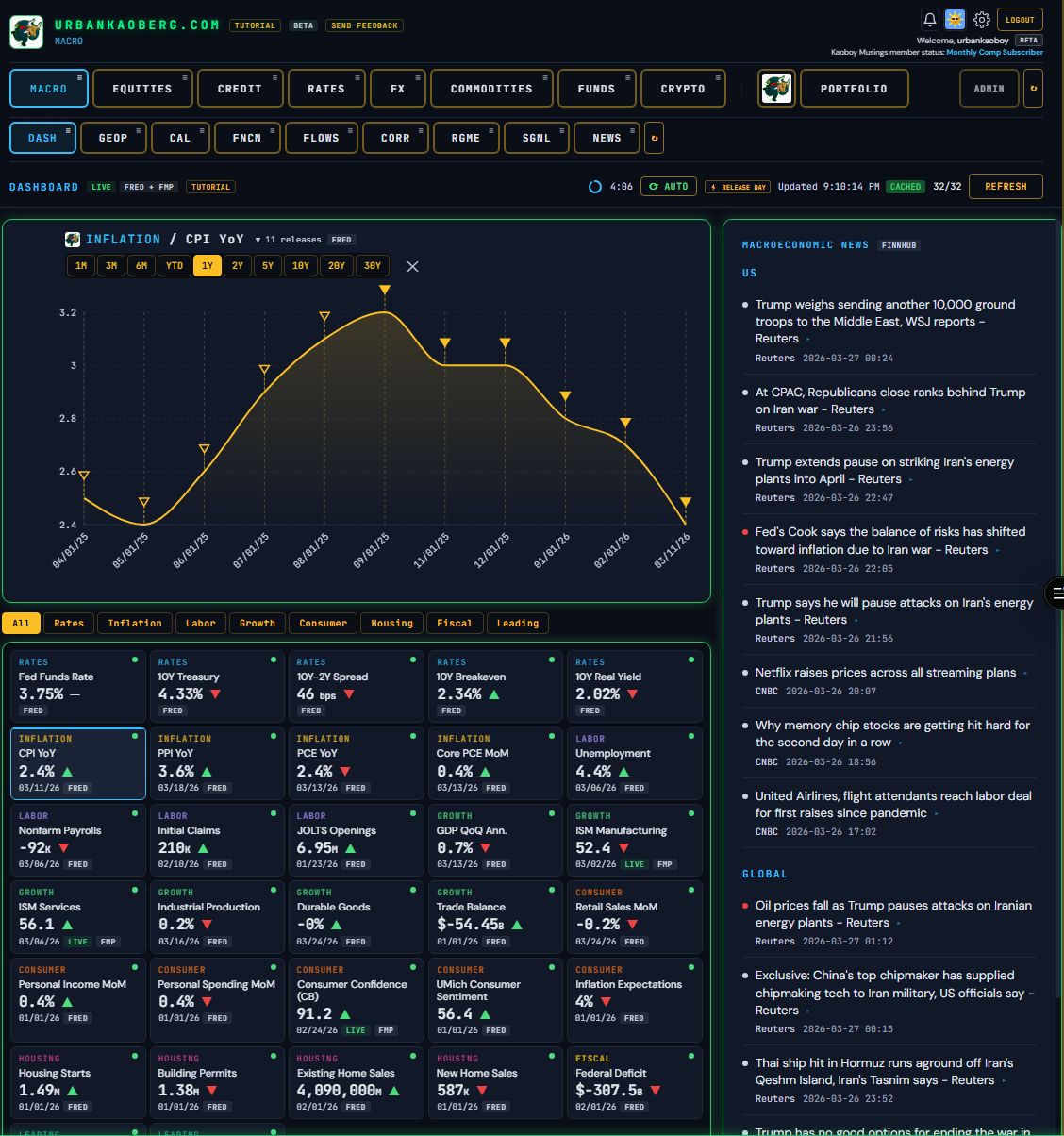
Introducing UrbanKaoberg.com:
“800+ commits. 55+ modules. 9 asset classes. 44 API endpoints. Almost 100K lines of code. All in less than a month by a person who hadn’t written code in 35 years.”
I built UrbanKaoberg.com in less than a month with AI. This piece is about my journey down one of the most frenetic, creative rabbit holes I have experienced and …
